How to Run gpt-oss Locally in NativeMind (Setup Guide)
NativeMind Team7 min read
OpenAI recently released gpt-oss, a small open-weight language model, sparking excitement in the AI community. It’s lean, immediately approachable, and lightweight, better for writing, coding, secure offline chatting, etc.
NativeMind now supports gpt-oss as one of its integrated local AI models. In this article, you'll learn how to use gpt-oss in NativeMind (with setup steps included) and the frequently asked questions you may have.
What is gpt-oss
gpt-oss is an open-weight language model released by OpenAI in August 2025. It’s designed to be:
- Lightweight – runs on consumer hardware
- Open – permissively licensed
Model details of gpt-oss
According to OpenAI, you have two options of gpt-oss models currently: gpt-oss:20b and gpt-oss:120b. Here are some differences between them, and you can choose one according to your needs.
Benefits of Running gpt-oss Locally
gpt-oss is OpenAI’s first general-purpose language model released with open weights and an Apache 2.0 license, allowing full commercial use and local deployment.
Unlike o3-mini or o4-mini, which are closed and API-only, gpt-oss can be run entirely on your own device or infrastructure—giving you full control over cost, latency, and data privacy.
The larger variant, gpt-oss-120b, uses a Mixture-of-Experts architecture to deliver strong reasoning performance with optimized efficiency. According to OpenAI, its performance is comparable to o4-mini, making it one of the most powerful open-weight models available today.
And for gpt-oss-20b, it’s comparable to o3-mini, which means that you can have an “offline ChatGPT” if you run it via NativeMind!
How to Set up gpt-oss in NativeMind
NativeMind, your private, open-weight, on-device AI assistant, now supports gpt-oss and other local LLMs like Deepseek, Qwen, Llama, Gemma, Mistral, etc. It’s very easy to set gpt-oss by connecting to Ollama, read the simple guide below.
Step 1: Setup Ollama in NativeMind
- Download and install NativeMind into your browser.
- Follow the simple guide to set up Ollama in your device.
Tips: You can skip this step if you have already setup NativeMind correctly on your device.
Step 2: Download gpt-oss via Ollama
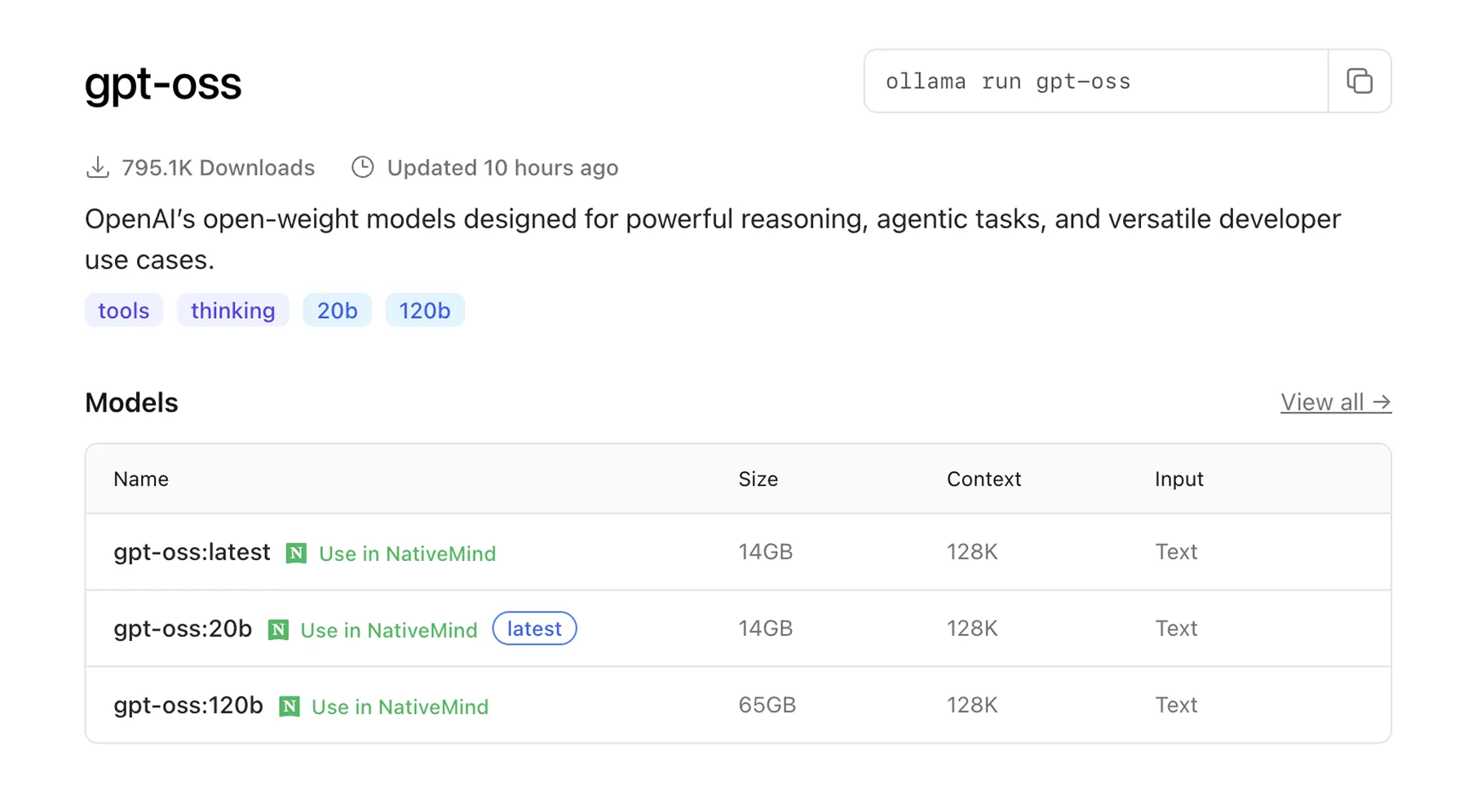
- Move to Ollama and find the gpt-oss model.
- Choose the size you want and click Use in NativeMind option to download.
Step 3: Run gpt-oss in NativeMind
- Open NativeMind in your browser, and now you can find the gpt-oss model.
- Select gpt-oss as your current model, and start using it smoothly.
FAQ about Using gpt-oss in NativeMind
1. Can I run gpt-oss without a GPU?
Yes. The smaller model gpt-oss:20b can run on a modern CPU with around 16GB RAM, though having a GPU will improve performance. The gpt-oss:120b variant generally requires a high-end GPU or server hardware.
2. Is gpt-oss free to use?
Yes. You can use gpt-oss totally free in NativeMind.
3. What can I use gpt-oss for?
You can use it for writing, summarizing, translating, coding, Q&A, and long-document analysis. With NativeMind, all of this can run fully offline, keeping your data private.
4. Which version should I choose: 20B or 120B?
- Choose 20B if you want fast, lightweight local AI on standard hardware.
- Choose 120B if you have the hardware and need maximum reasoning power for complex tasks.
Try It Now
After reading the setup guide above, you may have a general idea on gpt-oss and how to use it in NativeMind. Try it now to have a quick experience on using gpt-oss to summary web page content, translate multiple languages, chat on context, and even write blog posts, emails, or notes—without any data sending to cloud.
👉 Install NativeMind on Chrome or Firefox, or start with GitHub.
📁 Download gpt-oss via Ollama: https://ollama.com/library/gpt-oss
💬 Start chatting locally with NativeMind today—no cloud, no API key, no limits. Just speed, privacy, and productivity in your browser.