Show, Don't Tell: NativeMind's New Image Understanding
NativeMind Team2 min read
Have you ever found yourself in this situation: wanting to explain a complex chart but not knowing where to start? Looking at a flowchart packed with information on a webpage, but struggling to describe it accurately in words? Sometimes, words really can't compete with a single image.
Great news — NativeMind now supports image understanding! Simply upload your screenshots, photos, or charts, and let the AI directly "see" what you're looking at. It's like finally being able to point at your screen during a face-to-face conversation.
The entire process is seamless. Select files from your computer, paste from clipboard, or right-click any image on a webpage to add it directly to your conversation. The AI understands image content and provides insights that would otherwise require thousands of words to express.
Data Chart Analysis, Crystal Clear
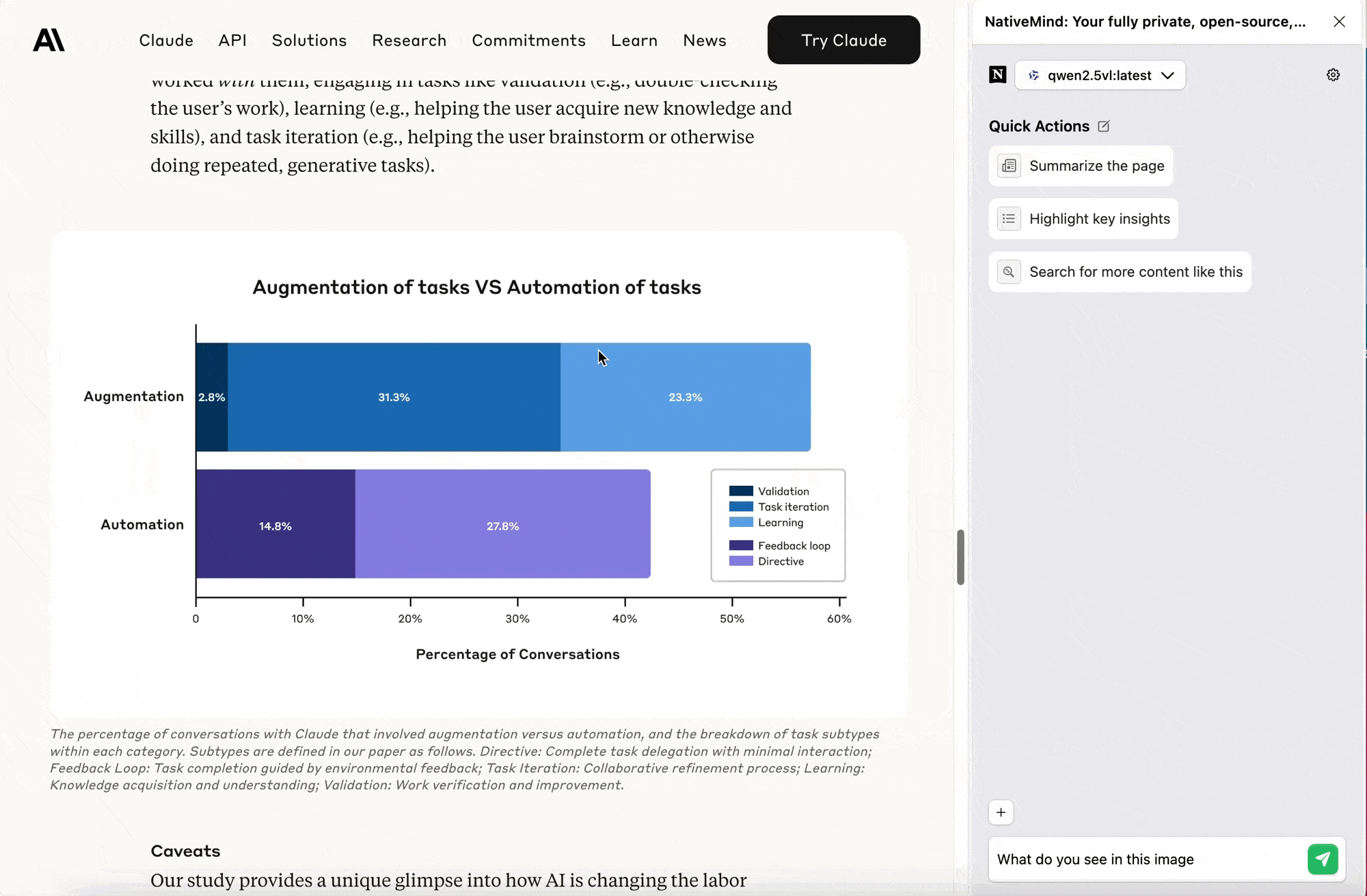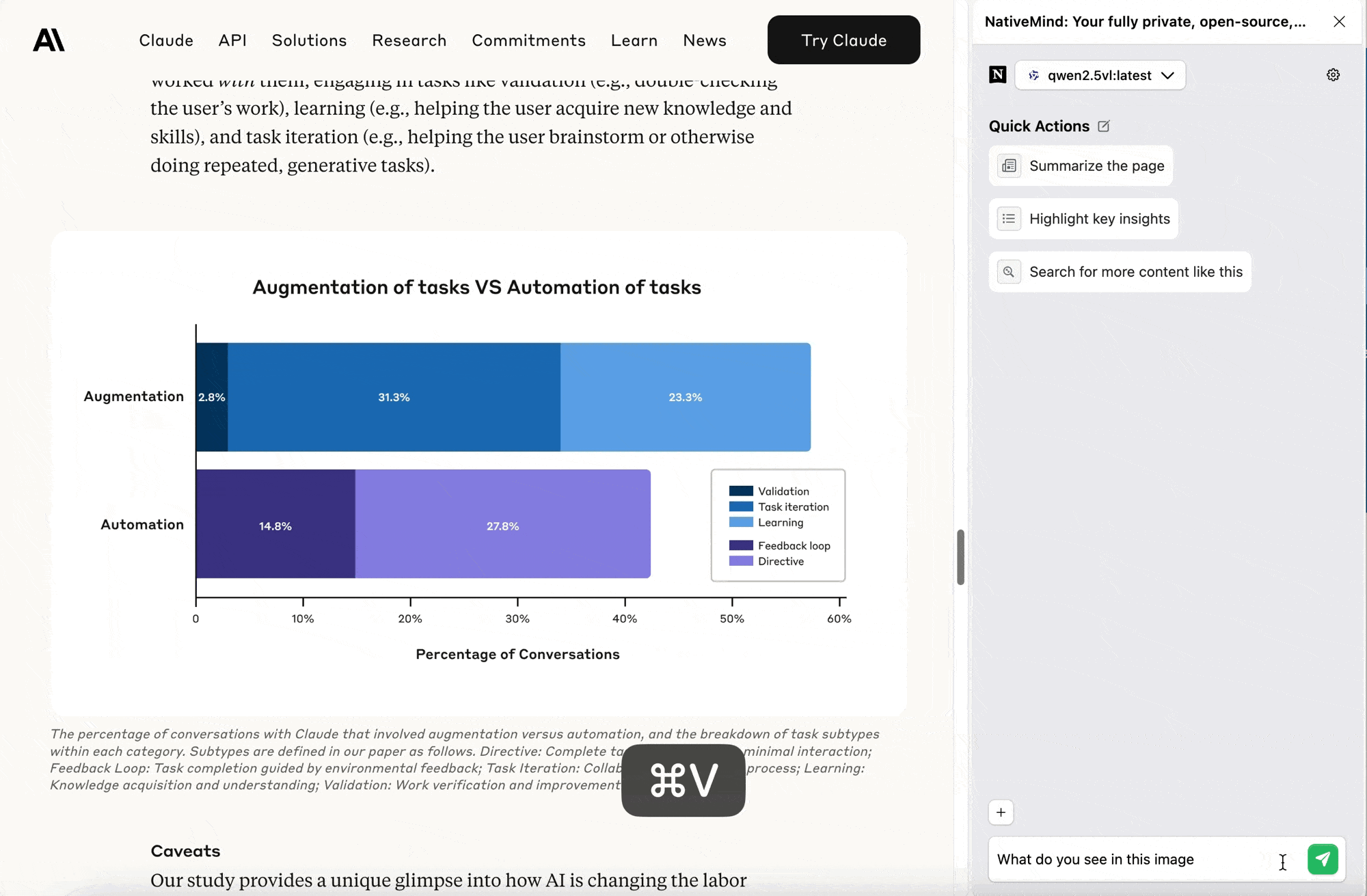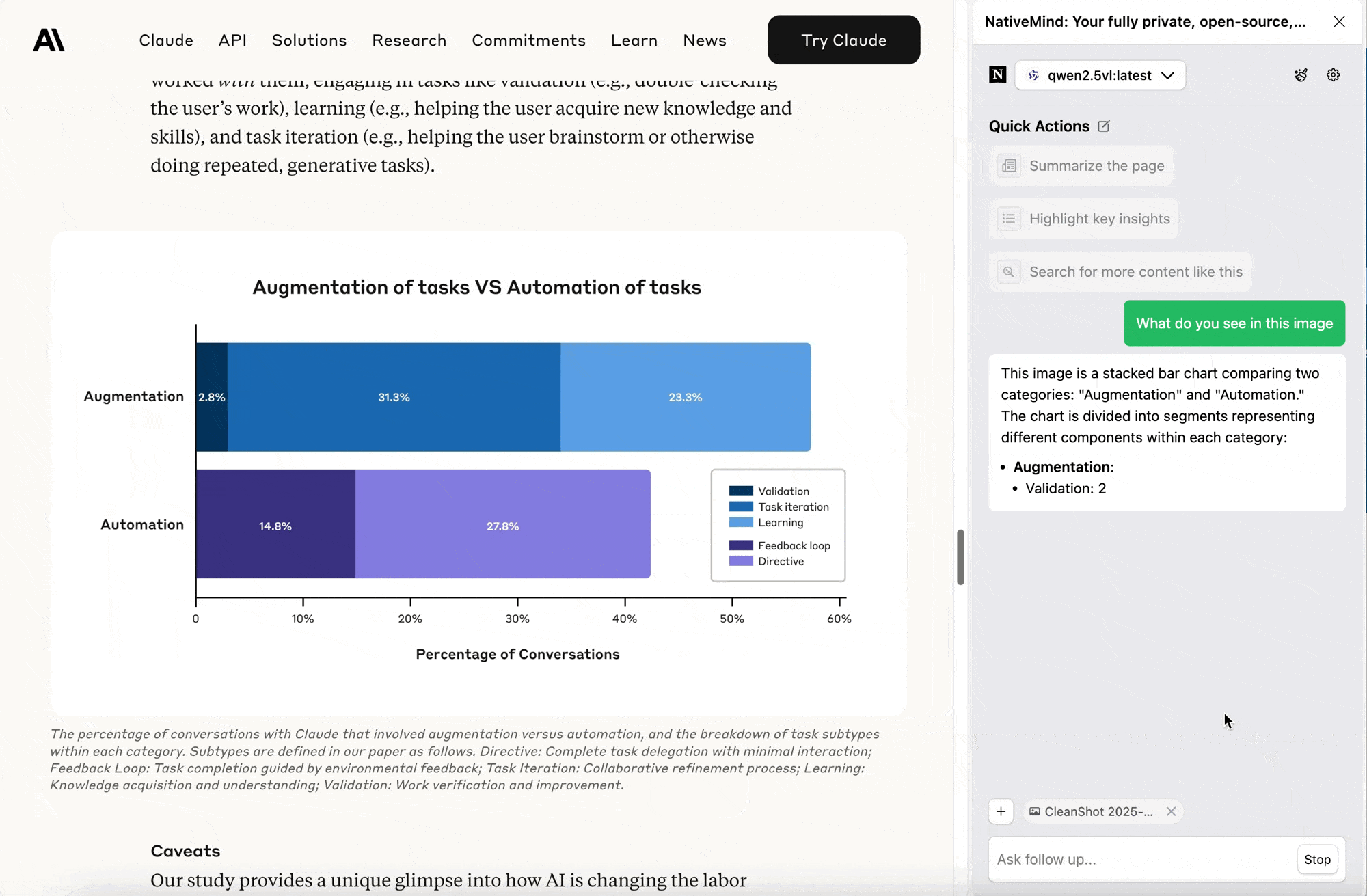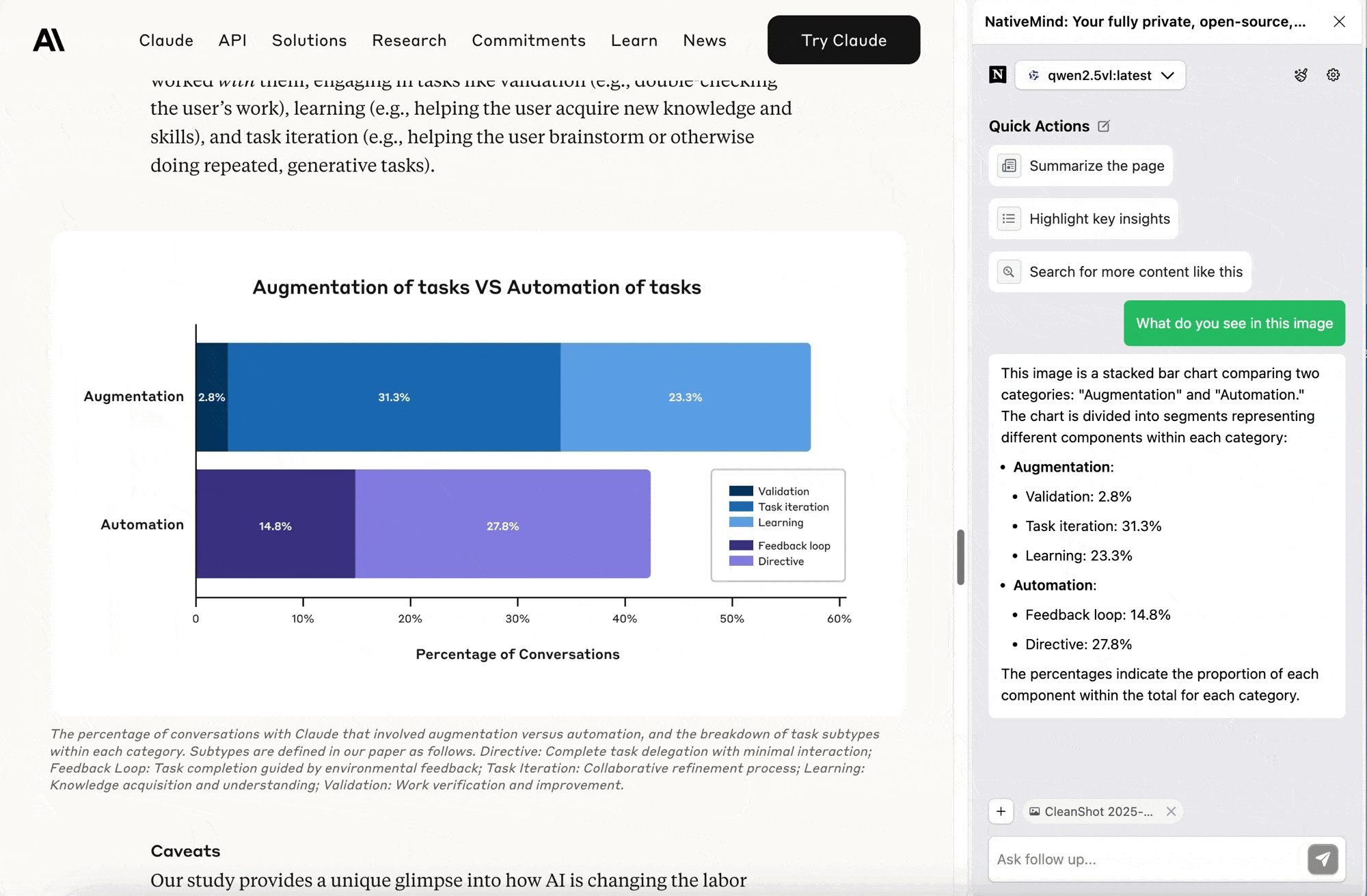
Confused while working with spreadsheets or dashboards? Upload a chart screenshot, and the AI will analyze trends, identify outliers, and summarize key insights for you. No more staring blankly at numbers or guessing what the data is trying to tell you.
It's like having a data analyst by your side who never gets tired of explaining things.
Browser Screenshot Interpretation, Made Easy
Encountering webpage errors? Interface issues? Technical documentation you can't understand? Just take a screenshot and upload it. The AI can recognize interface elements, read error messages, interpret complex technical content, and tell you exactly what's happening and how to fix it.
This feature is particularly useful for troubleshooting technical issues and learning new knowledge, saving you the hassle of copying and pasting text.
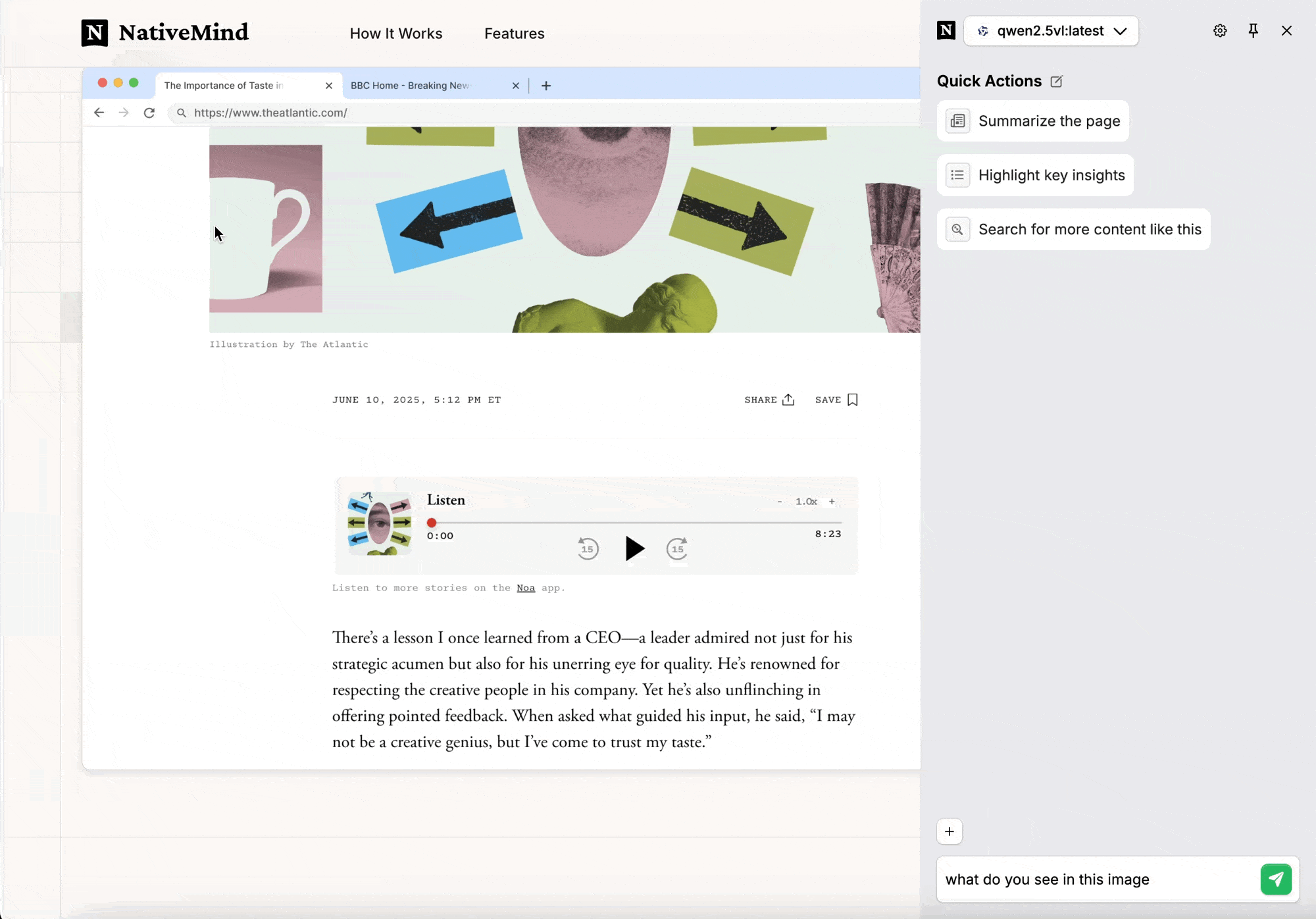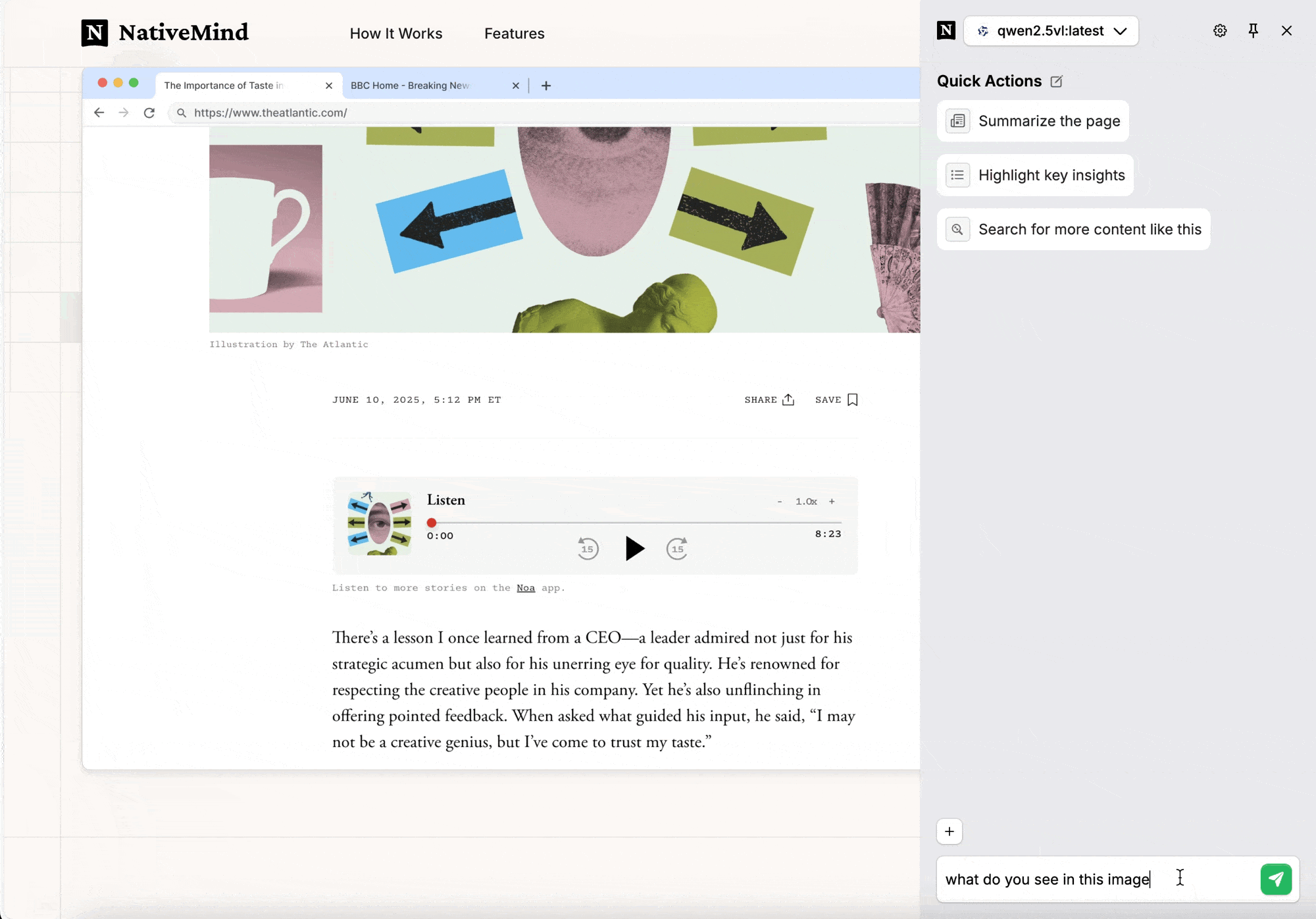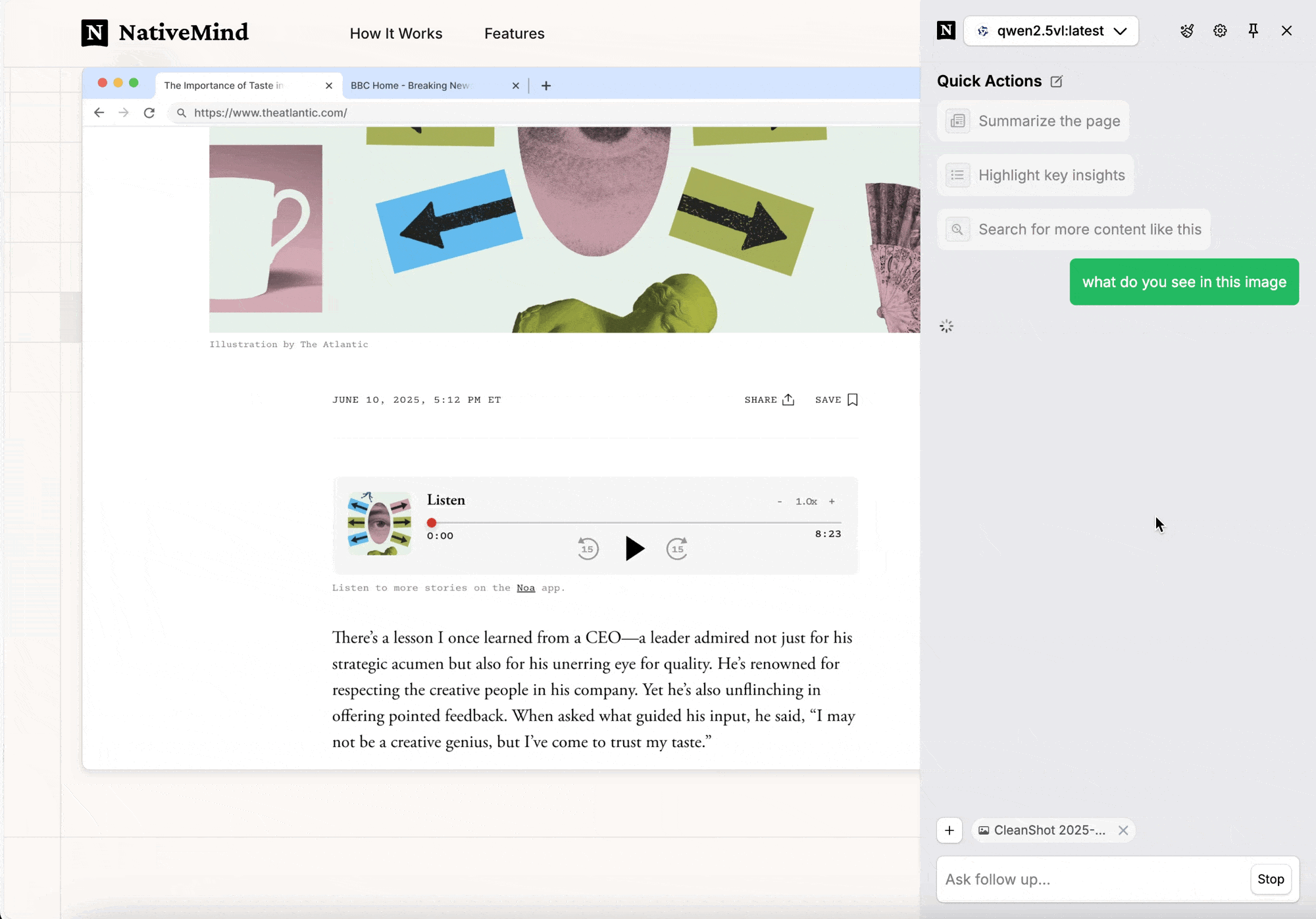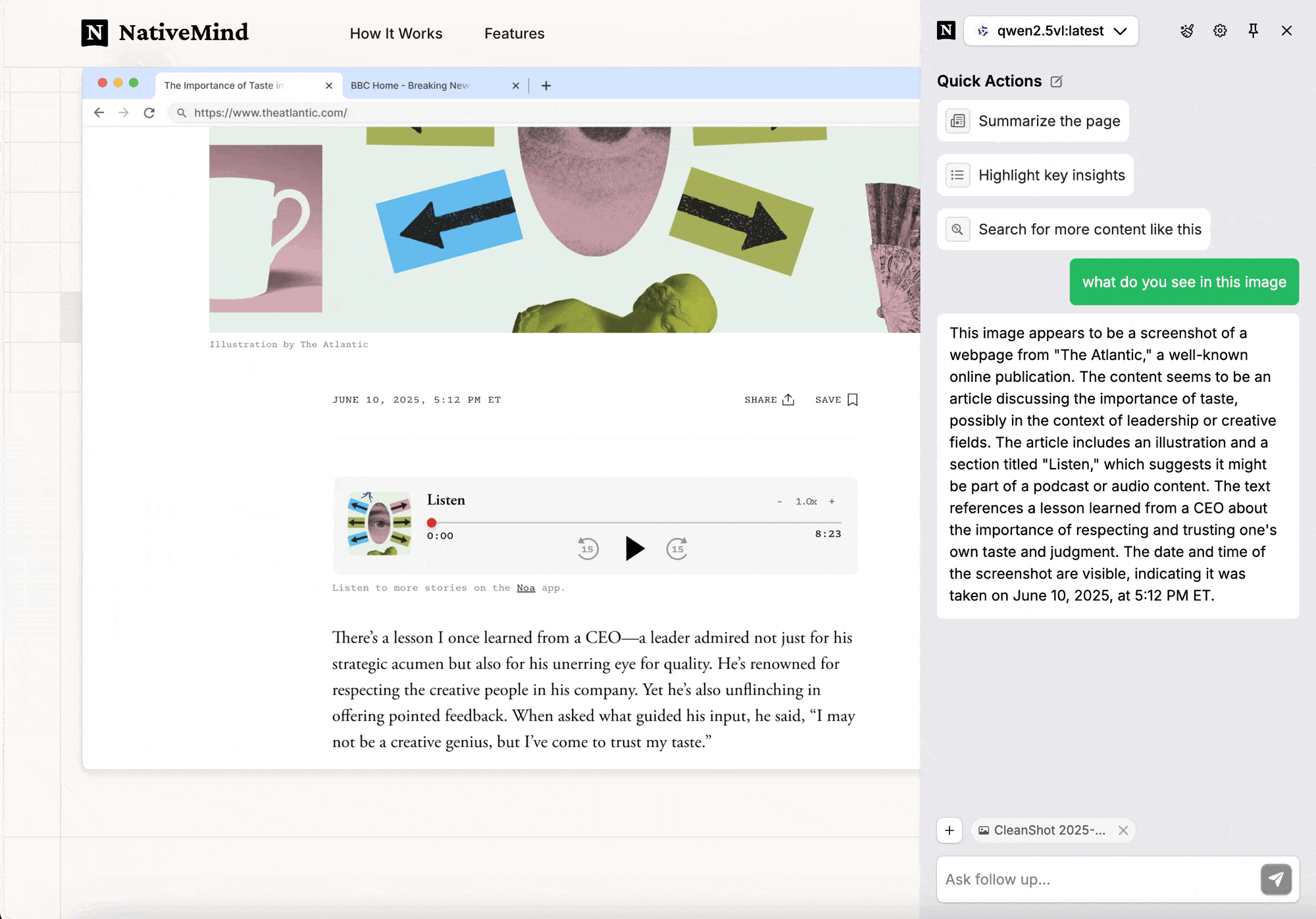
Recommended Vision Models: Local Processing, Privacy Assured
Of course, to use image analysis features, you'll need to choose Vision-capable models. We recommend running these excellent open-source Vision models through Ollama:
Privacy and Security, As Always
Just like all other NativeMind features, your image data remains completely private. Processing occurs through your chosen local Vision model, with no data uploaded to external servers.